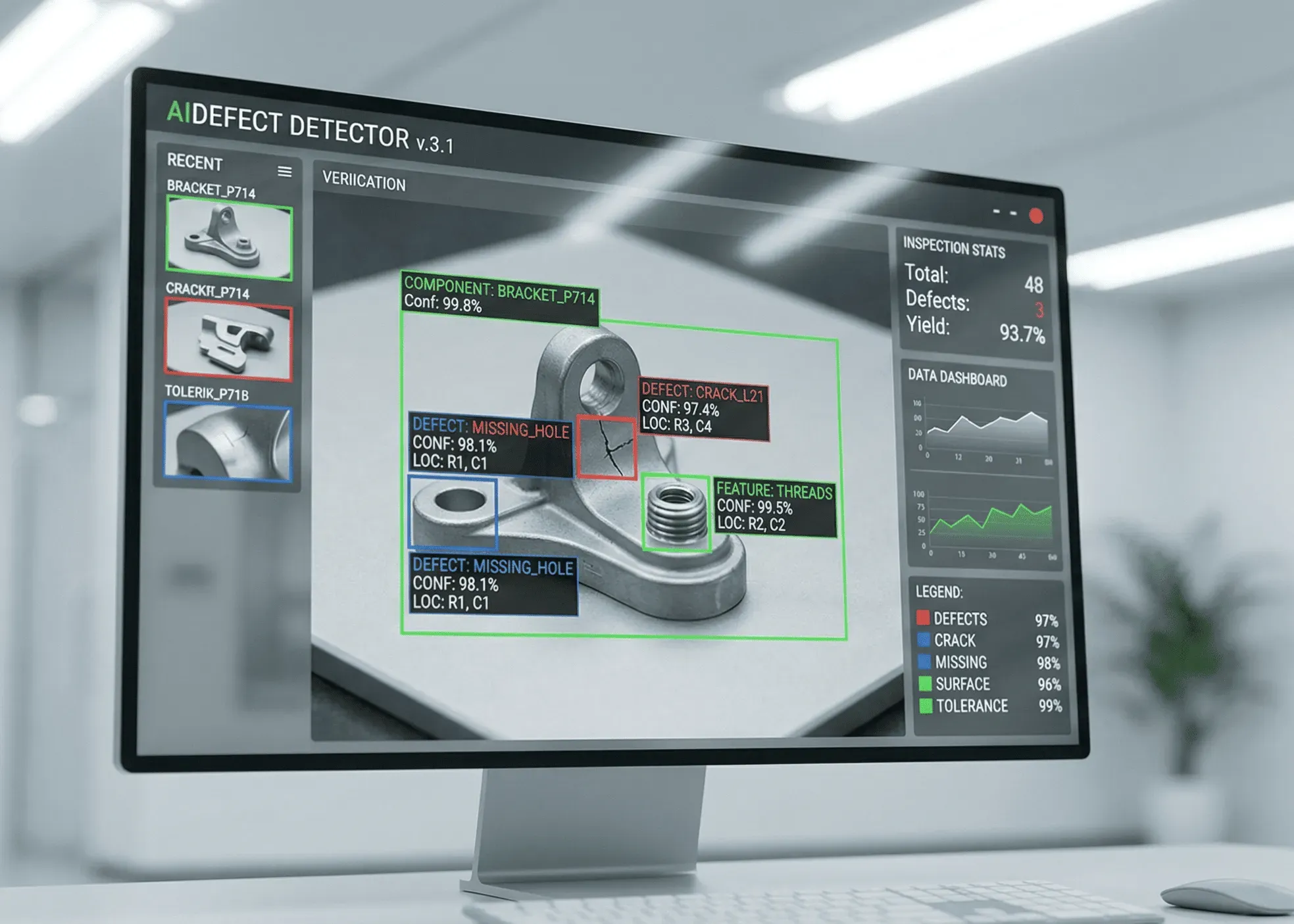
2026年4月2日、Google DeepMindがGemma 4をリリースした。Apache 2.0ライセンスの完全オープンモデルであり、商用利用・改変・再配布がすべて無料で許可されている。「AIを使いたいが、月額APIコストが読めない」「機密データを外部に出したくない」——中小企業が抱える2大課題を、Gemma 4は根本から解決する可能性がある。
本記事では、4つのモデルの特性比較から、企業ユースケース、導入手順、コスト比較までを網羅的に解説する。
Gemma 4リリースの概要
Gemma 4は、Googleの最上位モデルGeminiの技術をベースに設計されたオープンウェイトモデルだ。前世代のGemma 2から大幅に性能が向上し、特にコード生成・長文理解・多言語対応で飛躍的な改善が見られる。
横にスクロールして確認できます
| 項目 | 内容 |
|---|---|
| リリース日 | 2026年4月2日 |
| 開発元 | Google DeepMind |
| ライセンス | Apache 2.0(商用利用完全無料) |
| モデル数 | 4種類(2B / 4B / 26B MoE / 31B Dense) |
| 対応言語 | 英語・日本語を含む100言語以上 |
| 公開先 | Google Cloud、Hugging Face、Kaggle |
FREE DOWNLOAD
中小企業のDX推進「失敗を防ぐ5ステップ」ガイドを無料でお送りします
多くの企業がつまずくポイントを着手順に整理した無料ガイド。相談する前に、自社の現在地と進め方を掴めます。
4モデル比較表——どれを選ぶべきか
横にスクロールして確認できます
| モデル | パラメータ | アーキテクチャ | コンテキスト長 | 最適な用途 | 必要GPU(推論) |
|---|---|---|---|---|---|
| Gemma 4 2B Effective | 20億 | Dense | 32K | エッジAI、モバイル、IoT | 不要(CPU動作可) |
| Gemma 4 4B Effective | 40億 | Dense | 32K | チャットボット、要約、分類 | 4GB VRAM |
| Gemma 4 26B MoE | 260億(MoE) | Mixture of Experts | 128K | コード生成、データ分析 | 16GB VRAM |
| Gemma 4 31B Dense | 310億 | Dense | 256K | AIエージェント、複雑な推論 | 24GB VRAM |
MoE(Mixture of Experts)とは: 全パラメータのうち一部のみを各推論で活性化する手法。26Bモデルは実効的に約8B相当の計算量で動作し、コストパフォーマンスに優れる。
Apache 2.0ライセンスの意味——なぜ企業にとって重要か
Apache 2.0は、オープンソースソフトウェアのライセンスとしては最も緩い部類に入る。
横にスクロールして確認できます
| 許可される行為 | 詳細 |
|---|---|
| 商用利用 | 自社プロダクトへの組み込み、顧客向けサービスへの利用が無条件で可能 |
| 改変 | モデルのファインチューニング、蒸留、量子化が自由 |
| 再配布 | 改変後のモデルを第三者に配布・販売可能 |
| 特許付与 | コントリビューターから特許ライセンスが自動付与される |
Metaのllama(旧Llama)との違い: llamaはMeta独自ライセンスであり、月間アクティブユーザー7億人以上のサービスでの利用には別途ライセンスが必要。Gemma 4のApache 2.0にはそうした制限が一切ない。
企業にとっての実務的メリット: 法務部門でのライセンス審査が最小限で済み、導入の意思決定スピードが格段に速くなる。
FREE DOWNLOAD
AI導入チェックリスト(PoC 失敗要因 10項目)
情シス部門が PoC 前に押さえるべき失敗要因を10項目に整理した無料チェックリスト。
企業のユースケース3つ
ユースケース1:エッジAI(2B/4Bモデル → スマホ・IoTデバイスでオフライン推論)
2Bモデルはスマートフォン上でリアルタイム動作が可能なサイズだ。これにより、インターネット接続なしでAI推論が実行できる。
横にスクロールして確認できます
| 活用例 | 業種 | 効果 |
|---|---|---|
| 製品検品の画像判定 | 製造業 | 検品ラインに端末を設置し、不良品をリアルタイム検出 |
| 現場報告の音声テキスト化 | 建設業 | 電波が届かない現場でも音声から日報を自動生成 |
| 接客時のFAQ回答 | 小売・サービス業 | タブレット端末でオフラインでも顧客対応 |
コスト削減効果: クラウドAPIを使わないため、月額の推論コストがゼロになる。初期のデバイス費用のみ。
ユースケース2:コード生成・レビュー(26B MoE → 開発効率化)
26B MoEモデルは128Kトークンのコンテキスト長を持ち、大規模コードベースの理解と生成が可能だ。
横にスクロールして確認できます
| 活用シーン | 具体的な作業 | 期待効果 |
|---|---|---|
| コードレビュー自動化 | PRのdiffを入力し、バグ・セキュリティリスクを検出 | レビュー工数を50%削減 |
| レガシーコード変換 | COBOL→Java、VBA→Pythonのマイグレーション支援 | 変換工数を70%短縮 |
| テストコード生成 | 既存コードからユニットテストを自動生成 | カバレッジ向上、手作業の削減 |
社内で完結するメリット: ソースコードを社外APIに送信する必要がないため、知的財産の保護とセキュリティポリシーへの適合が容易。
関連記事:AIエージェントとは?仕組み・活用事例・導入費用をわかりやすく解説
ユースケース3:AIエージェント構築(31B Dense → 256Kコンテキスト)
31B Denseモデルは256Kトークン(日本語約12万字相当)のコンテキストウィンドウを持つ。これにより、長大な社内文書やマニュアル全体を一度に読み込んだうえで推論を行うAIエージェントが構築できる。
横にスクロールして確認できます
| エージェント例 | 機能 | 対象業種 |
|---|---|---|
| 社内ナレッジBot | 規程・マニュアル・過去議事録から回答を生成 | 全業種 |
| 契約書レビューAgent | 契約書全文を読み込み、リスク条項を自動検出 | 士業・法務 |
| 調達最適化Agent | 過去の発注履歴・価格データをもとに最適な発注先を提案 | 製造・小売業 |
クラウドAPI vs ローカル実行のコスト比較
横にスクロールして確認できます
| 項目 | クラウドAPI(GPT-4o相当) | ローカル実行(Gemma 4 26B MoE) |
|---|---|---|
| 初期費用 | 0円 | GPU搭載PC:30〜80万円 |
| 月額コスト(月10万トークン処理) | 約3〜8万円 | 電気代のみ(約2,000〜5,000円) |
| 月額コスト(月100万トークン処理) | 約30〜80万円 | 電気代のみ(約5,000〜1万円) |
| データ送信 | 外部サーバーに送信 | 社内で完結 |
| カスタマイズ | 不可(APIの範囲内) | ファインチューニング自由 |
| 12か月総コスト(100万トークン/月) | 360〜960万円 | 36〜92万円 |
損益分岐点の目安: 月のAPI利用料が5万円を超える場合、ローカル実行への移行を検討する価値がある。処理量が増えるほどコストメリットが拡大する。
導入手順——3つのルート
ルート1:Google Cloud(Vertex AI)
- Google Cloudアカウントを作成
- Vertex AI Model Gardenから「Gemma 4」を選択
- エンドポイントをデプロイ(数クリックで完了)
- APIキーを発行し、アプリケーションから呼び出し
メリット: インフラ管理不要。従量課金だがGCP無料枠($300)で試用可能。
ルート2:Hugging Face
- Hugging Faceアカウントを作成
google/gemma-4-26b-moeモデルページからダウンロードtransformersライブラリで推論実行- 必要に応じてファインチューニング
メリット: コミュニティのサポートが充実。量子化版(GGUF形式)も入手可能。
ルート3:ローカル実行(Ollama / llama.cpp)
ollama pull gemma4:26b-moeでモデルをダウンロードollama serveでローカルAPIサーバーを起動http://localhost:11434からAPI呼び出し- 社内アプリケーションと連携
メリット: 外部通信なし。データが社外に出ない。ランニングコストが最小。
よくある質問(FAQ)
Q. Gemma 4は日本語に対応していますか?
はい。Gemma 4は100言語以上に対応しており、日本語の生成品質は前世代(Gemma 2)から大幅に向上している。ただし、英語と比較すると精度に差がある場合があるため、業務利用前に日本語タスクでの精度検証を推奨する。
Q. GPT-4oやClaude 3.5と比べてどうですか?
31B Denseモデルは、ベンチマーク上でGPT-4o miniやClaude 3.5 Haikuに匹敵する性能を示している。ただし、GPT-4oやClaude Opusといった最上位モデルとの比較では差がある。**重要なのは「十分な性能を無料で得られる」**というコスト構造の優位性だ。
Q. セキュリティ上の懸念はありますか?
ローカル実行ではデータが外部に一切送信されないため、クラウドAIよりもセキュリティリスクは低い。ただし、モデル自体のハルシネーション(事実と異なる出力)のリスクは他のAIと同様に存在する。重要な判断には必ず人間の確認ステップを組み込むべきだ。
Q. 中小企業がまず試すなら、どのモデルがおすすめですか?
26B MoEモデルが最もバランスが良い。 128Kのコンテキスト長があり、コード生成からドキュメント要約まで幅広く対応できる。16GB VRAMのGPU(RTX 4060 Ti 16GBなど、約6〜8万円)で動作する。
まとめ:オープンモデルが「AI導入の民主化」を加速する
Gemma 4の登場により、高性能なAIモデルを無料で商用利用できる時代が本格的に到来した。中小企業にとって、これは以下の意味を持つ。
横にスクロールして確認できます
| ポイント | 内容 |
|---|---|
| コスト障壁の解消 | 月額数十万円のAPIコストが不要に |
| データ主権の確保 | 機密データを社外に出さずにAI活用が可能 |
| カスタマイズの自由 | 自社業務に特化したモデルを構築可能 |
| ベンダーロックインの回避 | 特定のクラウドサービスに依存しない |
今すぐ取るべきアクション:
- Ollamaで26B MoEモデルをダウンロードし、自社業務で試す(所要時間:30分)
- 社内のどの業務にAIを適用できるか洗い出す
- PoC(概念実証)を実施し、効果を数値で把握する
関連記事:AIエージェント実践ロードマップ|中小企業の業務自動化を3ステップで実現
関連記事:AI導入の費用対効果を正しく計算する方法|ROI算出テンプレート付き
関連記事:NEC自動交渉AIエージェントがGartner掲載|調達業務のAI自動化が本格化する理由
オープンAIモデルの企業導入、何から始めるか迷っていませんか?
GXOでは、Gemma 4をはじめとするオープンモデルの選定・PoC設計・社内インフラ構築まで一貫して支援しています。「自社で動かせるか試したい」「APIコストを削減したい」という方は、まず無料相談をご利用ください。
※ 営業電話はしません | オンライン対応可 | 相談だけでもOK
関連記事:GXOの導入事例一覧はこちら
GXO実務追記: AI開発・生成AI導入で発注前に確認すべきこと
この記事のテーマは、単なるトレンド紹介ではなく、業務選定、データ整備、セキュリティ、PoCから本番化までの条件を決めるための検討材料です。検索で情報収集している段階でも、発注前に次の観点を整理しておくと、見積もりのブレ、手戻り、ベンダー依存を減らせます。
まず決めるべき3つの論点
横にスクロールして確認できます
| 論点 | 確認する内容 | 未整理のまま進めた場合のリスク |
|---|---|---|
| 目的 | 売上拡大、工数削減、リスク低減、顧客体験改善のどれを優先するか | 成果指標が曖昧になり、PoCや開発が終わっても投資判断できない |
| 範囲 | 対象部署、対象業務、対象データ、対象システムをどこまで含めるか | 見積もりが膨らむ、または重要な連携が後から漏れる |
| 体制 | 自社責任者、現場担当、ベンダー、保守運用者をどう置くか | 要件確認が遅れ、納期遅延や品質低下につながる |
費用・期間・体制の目安
横にスクロールして確認できます
| フェーズ | 期間目安 | 主な成果物 | GXOが見るポイント |
|---|---|---|---|
| 事前診断 | 1〜2週間 | 課題整理、現行確認、投資判断メモ | 目的と範囲が商談前に整理されているか |
| 要件定義 / 設計 | 3〜6週間 | 要件一覧、RFP、概算見積、ロードマップ | 見積比較できる粒度になっているか |
| PoC / MVP | 1〜3ヶ月 | 検証環境、効果測定、リスク評価 | 本番化判断に必要な数値が取れるか |
| 本番導入 | 3〜6ヶ月 | 本番環境、運用設計、教育、改善計画 | 導入後の運用責任と改善サイクルがあるか |
発注前チェックリスト
- AIで置き換える業務ではなく、成果が測れる業務を選んだか
- 参照データの所有者、更新頻度、権限、機密区分を整理したか
- PoC成功条件を精度、時間削減、CV改善、問い合わせ削減などで数値化したか
- プロンプトインジェクション、個人情報、ログ保存、モデル選定のルールを決めたか
- RAG/エージェントの回答を人が監査する運用を設計したか
- 本番化後の費用上限、API使用量、障害時フォールバックを決めたか
参考にすべき一次情報・公的情報
- 経済産業省 AI事業者ガイドライン関連情報
- デジタル庁 AI関連情報
- OpenAI Platform Documentation
- Anthropic Claude Documentation
- OWASP Top 10 for LLM Applications
上記の一次情報は、社内稟議やベンダー比較の根拠として使えます。一方で、公開情報だけでは自社の現行システム、業務フロー、データ状態、予算制約までは判断できません。記事で一般論を把握した後は、自社条件に落とした診断が必要です。
GXOに相談するタイミング
次のいずれかに当てはまる場合は、記事を読み進めるだけでなく、早めに相談した方が安全です。
- 見積もり依頼前に、要件やRFPの粒度を整えたい
- 既存ベンダーの提案が妥当か第三者視点で確認したい
- 補助金、AI、セキュリティ、レガシー刷新が絡み、判断軸が複雑になっている
- 社内稟議で費用対効果、リスク、ロードマップを説明する必要がある
- PoCや診断で終わらせず、本番導入と運用改善まで進めたい
Google Gemma 4 完全ガイド|Apache 2.0で商用無料のAIモデル4種を企業でどう活用するかを自社条件で診断したい方へ
GXOが、現状整理、RFP/要件定義、費用対効果、ベンダー比較、導入ロードマップまで実務目線で確認します。記事の一般論を、自社の投資判断に使える形へ落とし込みます。
※ 初回相談では営業資料の説明よりも、現状・課題・判断材料の整理を優先します。